How slow is Python's string concatenation vs. str.join?
From: Efficient String Concatenation
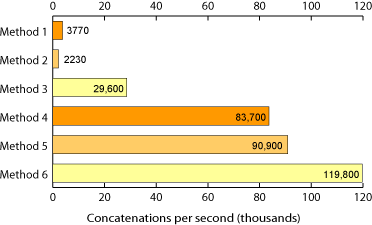
Method 1:
def method1(): out_str = '' for num in xrange(loop_count): out_str += 'num' return out_strMethod 4:
def method4(): str_list = [] for num in xrange(loop_count): str_list.append('num') return ''.join(str_list)Now I realise they are not strictly representative, and the 4th method appends to a list before iterating through and joining each item, but it's a fair indication.
String join is significantly faster then concatenation.
Why? Strings are immutable and can't be changed in place. To alter one, a new representation needs to be created (a concatenation of the two).
My original code was wrong, it appears that + concatenation is usually faster (especially with newer versions of Python on newer hardware)
The times are as follows:
Iterations: 1,000,000 Python 3.3 on Windows 7, Core i7
String of len: 1 took: 0.5710 0.2880 secondsString of len: 4 took: 0.9480 0.5830 secondsString of len: 6 took: 1.2770 0.8130 secondsString of len: 12 took: 2.0610 1.5930 secondsString of len: 80 took: 10.5140 37.8590 secondsString of len: 222 took: 27.3400 134.7440 secondsString of len: 443 took: 52.9640 170.6440 secondsPython 2.7 on Windows 7, Core i7
String of len: 1 took: 0.7190 0.4960 secondsString of len: 4 took: 1.0660 0.6920 secondsString of len: 6 took: 1.3300 0.8560 secondsString of len: 12 took: 1.9980 1.5330 secondsString of len: 80 took: 9.0520 25.7190 secondsString of len: 222 took: 23.1620 71.3620 secondsString of len: 443 took: 44.3620 117.1510 secondsOn Linux Mint, Python 2.7, some slower processor
String of len: 1 took: 1.8840 1.2990 secondsString of len: 4 took: 2.8394 1.9663 secondsString of len: 6 took: 3.5177 2.4162 secondsString of len: 12 took: 5.5456 4.1695 secondsString of len: 80 took: 27.8813 19.2180 secondsString of len: 222 took: 69.5679 55.7790 secondsString of len: 443 took: 135.6101 153.8212 secondsAnd here is the code:
from __future__ import print_functionimport timedef strcat(string): newstr = '' for char in string: newstr += char return newstrdef listcat(string): chars = [] for char in string: chars.append(char) return ''.join(chars)def test(fn, times, *args): start = time.time() for x in range(times): fn(*args) return "{:>10.4f}".format(time.time() - start)def testall(): strings = ['a', 'long', 'longer', 'a bit longer', '''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''', '''this is a really long string that's so long it had to be triple quoted and contains lots of superflous characters for kicks and gigles @!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''', '''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.'''] for string in strings: print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")testall()
The existing answers are very well-written and researched, but here's another answer for the Python 3.6 era, since now we have literal string interpolation (AKA, f-strings):
>>> import timeit>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)0.14618930302094668>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)0.23334730707574636>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)0.14985873899422586Test performed using CPython 3.6.5 on a 2012 Retina MacBook Pro with an Intel Core i7 at 2.3 GHz.
This is by no means any formal benchmark, but it looks like using f-strings is roughly as performant as using += concatenation; any improved metrics or suggestions are, of course, welcome.